배경
Admin 시스템에서 JVM Hang이 매주 터졌습니다. 원인을 찾으려면 수백만 줄의 로그를 직접 읽어야 했는데, 1시간 넘게 걸려도 뚜렷한 원인을 못 잡는 경우가 많았습니다. 결국 서버를 재기동하고, 다음 주에 또 같은 일이 반복되는 구조였습니다.

해결 방법
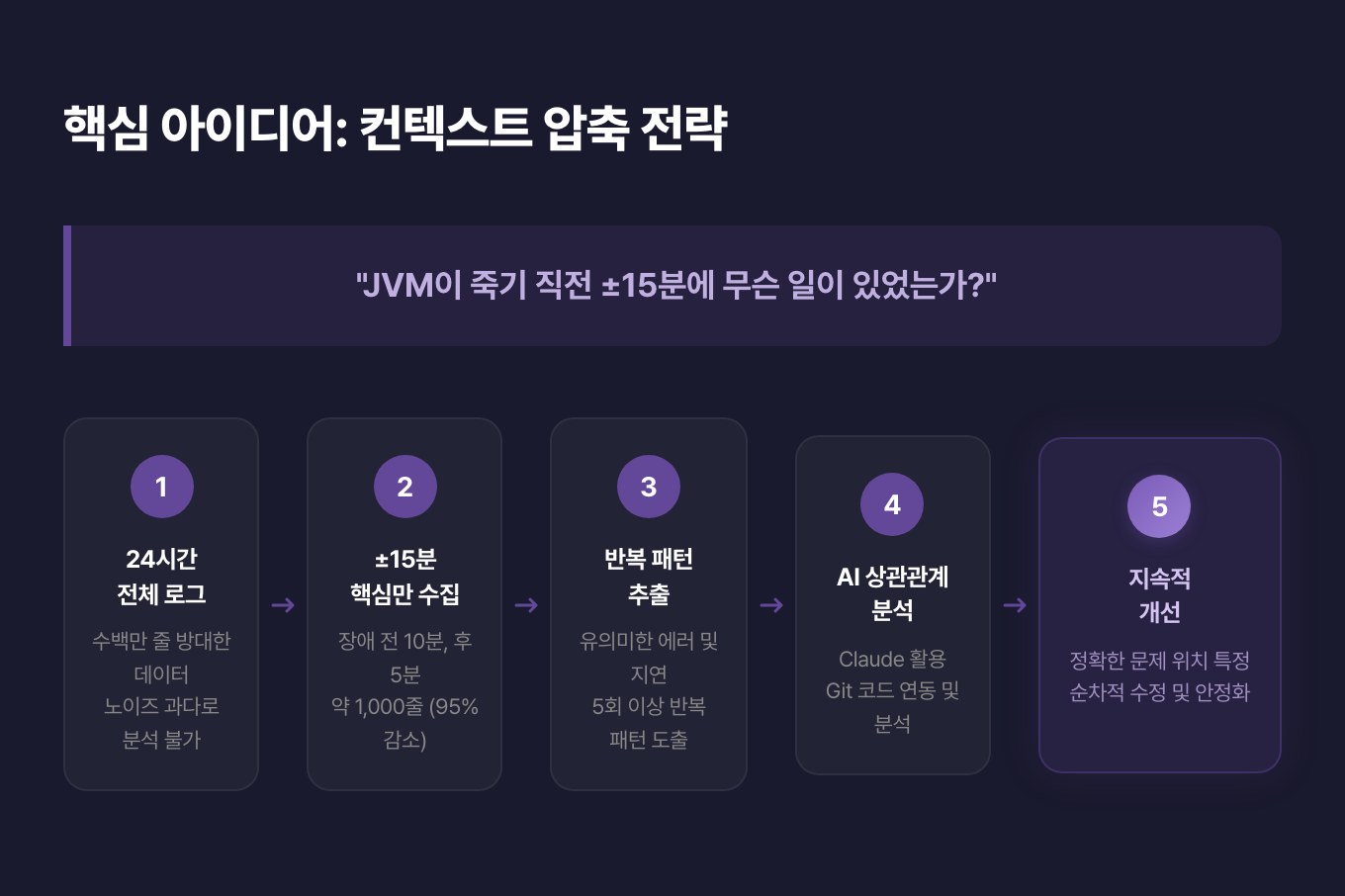
“JVM이 죽기 직전 ±15분에 무슨 일이 있었는가?” — 이 질문 하나를 중심으로, 컨텍스트 압축 전략 기반의 AI 실시간 로그 모니터링 시스템을 만들었습니다.
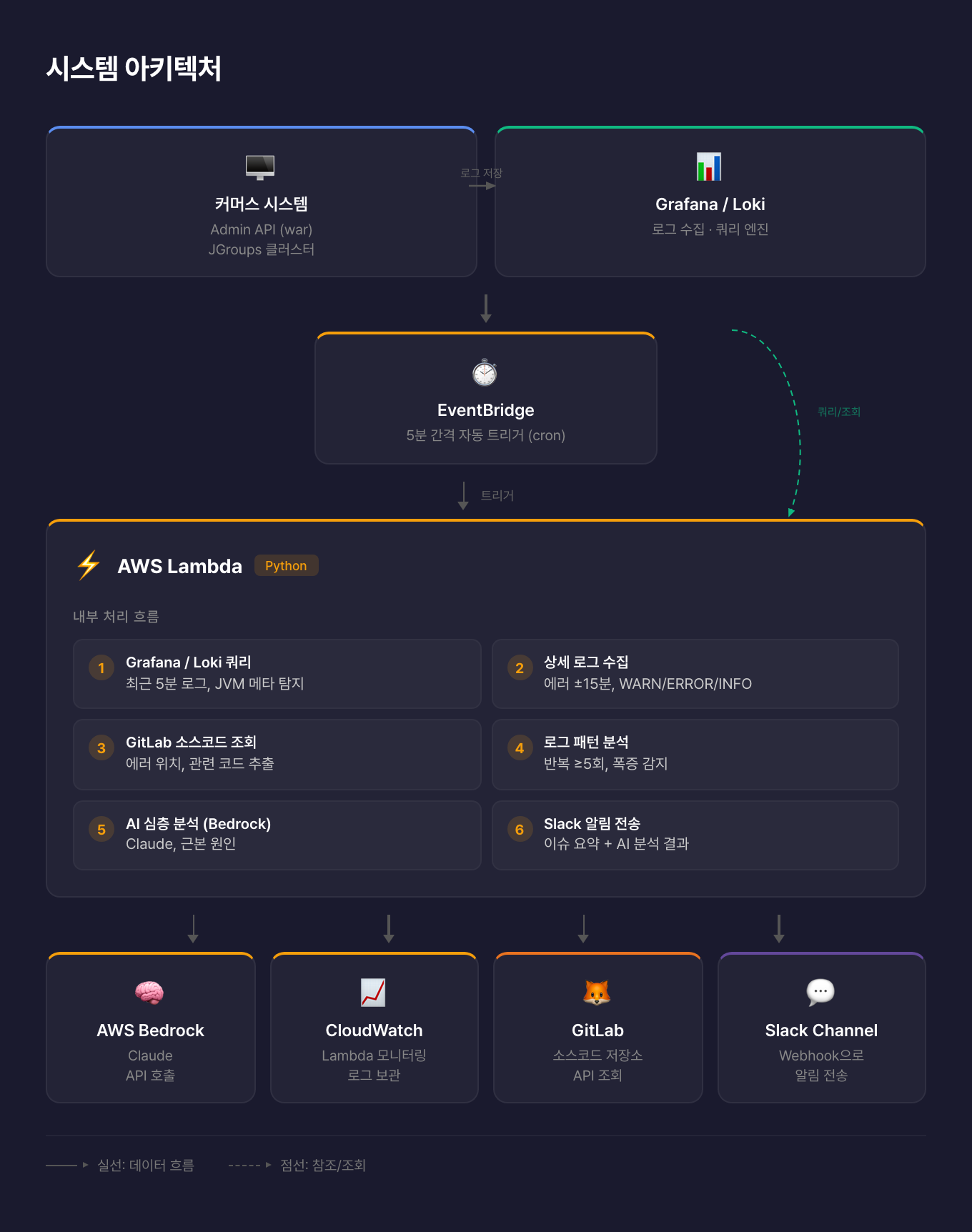
시스템 아키텍처
EventBridge가 5분 주기로 Lambda를 트리거하고, Grafana/Loki에서 로그를 수집한 뒤 Bedrock AI로 심층 분석하여 Slack으로 결과를 전송합니다.
핵심 메커니즘
데이터 전처리와 AI 분석을 2단계로 나누어 처리합니다. 24시간 전체 로그를 ±15분으로 압축(99% 노이즈 감소)한 뒤, Bedrock AI가 장애 원인을 분석하고 Slack으로 리포팅합니다.

실제 해결 사례
시스템 도입 후 Localization key 반복 조회로 인한 JVM 지연을 5분 만에 자동 탐지하고, AI가 정확한 원인을 분석하여 Slack으로 즉시 알림을 전송한 사례입니다.

지속적 개선
AI 분석을 통해 식별한 고질적인 핵심 원인 3건을 우선 해결했습니다.
- DateUtils 날짜 포맷 에러 로그 개선: invalid 로그 80회 반복 제거
- Admin 콘솔 Localization 부하 제거: 무효한 Key 조회 400회+ 해소
- 매출 상세 CSV 다운로드 메모리 최적화: Chunk 분할 처리로 리팩토링

효과
단번에 모든 장애 요소가 사라지지는 않겠지만, 이 시스템을 통해 그동안 발생했던 에러 패턴들을 식별하고 불안정 요소를 단계적으로 걸어내는 중입니다.

눈여겨볼 점
- 24시간 로그를 ±15분으로 좁히고, Python 전처리로 99% 노이즈를 제거한 뒤 AI에 넘깁니다. "AI에 무엇을 먹일 것인가"를 정확히 이해한 설계입니다.
- 실제로 3건의 고질 이슈를 잡았습니다. DateUtils null-check(invalid 로그 80→0), Localization key 부하 제거(무효 조회 400건+ 해소), CSV 다운로드 메모리 최적화(Chunk 분할로 주간 JVM Hang 제거)까지 — 단순 알림이 아니라 장애를 실제로 근절하는 도구로 동작하고 있습니다.
- 월 $8-9로 운영됩니다. EventBridge + Lambda + Bedrock 서버리스 조합이라 인프라 부담 없이 5분 주기 상시 모니터링이 가능합니다. 분석 결과도 로그 요약이 아니라 화면별 장애 분석, 재현 시나리오, 코드 수정 가이드까지 포함해서 바로 액션을 취할 수 있는 수준입니다.